重叠社区检测
背景
同构图是指每个节点的类型相同,那么其他属性的数据只能通过人工刻画的方式融入到节点特征或边的信息中;而异构图能把其他属性的数据直接定义到图结构中,不依赖人工,更好地刻画实际情况。 但在异构图中做社区检测时,同一个节点可能属于不同的社区,就要用到重叠社区检测算法,本文简单介绍下。
举例
LinkComm
Linkcomm 是边划分(Link partition)方法中的代表,以边而不是点为基本元素进行社区划分,就能使同一个点属于不同的社区。其他原理类似 louvain 的做法。 边-边相似度的定义:两条边非公共节点的邻居节点交并比。
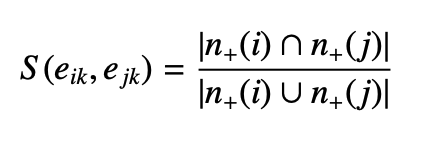
如果考虑边权,就用用平方和融入到公式中。
社团密度定义(社团划分的好坏):(社区实际的边数 - 要连通的基本边数) / (全连接社区边数 - 基本边数)
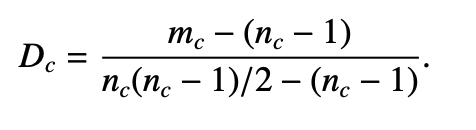
按照边-边相似度大小排序进行边的合并,选出使得社团整体密度最大的分团状态作为最终状态。
跟 Louvain 对比 | - | link comm | louvain | | —- | —- | | 优点 | 按边边相似度顺序合并 | 随机 | | 缺点 | 每次合并两个社团 | 每次移动一个节点 | | 缺点 | 一次迭代求最优 | 多轮迭代直至收敛 |
CPM-派系过滤
CPM是Clique Percolation(团渗透)类方法的代表,包含两步: 1.寻找 k 个节点的完全子图,每个完全子图成为一个 k-派系 2.两个k-派系如果有k-1个公共节点,那他们就属于同一个社团,按此方式连边组成的k-派系的联通分支集合,就是一个社团。
特点 1.超参k由人工设置,4-6,社团的划分结果比较依赖该值。 2.主要适用于联通子图较多的场景。 3.复杂度较高,能支持节点数量不多,要根据实际数据情况适配建图方式。 4.不能加入边权信息
SLPA
便签传播算法拓展,利用周围节点的标签给当前节点标签不断赋值迭代,直至稳定。
初始化:每个节点都属于唯一不同的标签
迭代T次:随机选择一个节点,将邻居节点的标签汇总,挑选频率最高的,作为本轮当前节点的标签。将每轮的标签结果存储下来,当需要当前节点贡献标签时,就从历史多轮的标签中,按频率抽样输出。
成团:每个节点保留占比 > x 的标签作为当前节点的标签,可能存在多个。同一标签的节点则属于同一个社团。
特点: 1.迭代成本高 2.猜测:初始化每个节点属于不同的社区,导致比较难收敛,收敛之后精度应该很高,召回不高。
LEMON
LEMON是种子扩张类算法的代表,已知部分节点和所属的社区,来扩充同属于该社区的其他节点。扩大召回的使用场景偏小,细节待了解。 特点:用来做扩召回比较合适。