社区发现算法 - Louvain
概述
图是由节点和节点之间的边构成的一种结构,比如社交网络中人与人之间的关系、全球各个城市的交通连接情况,都可以表达成一个图结构。
社区发现是指图结构中存在聚集的一个节点集合,比如社交网络中的一个个人际圈子会组成一个个社团,在交通的图结构中,每个国家的城市集合就可以表达为一个社团。
社区发现发现算法就是依据图结构数据,来寻找聚集性社区的算法,正确的社区划分对下游业务应用有重要意义。louvain 是最常用的社区发现算法,以优化模块度为目标对群体进行划分。
模块度定义
模块度是对社区划分好坏程度的一种度量,当社区内部的点之间连边越多,社区之间的点连边越少时,模块度越大,表示当前的社区划分情况越好,公式定义如下:
\[Q=\frac{1}{2m}\sum_{i,j}{(A_{i,j}-\frac{k_i*k_j}{2m})*\delta(c_i,c_j)}\]其中 $m=\sum\limits_{i,j}{A_{ij}}$ 表示所有边权和,$A_{ij}$ 表示节点 $i$ 和 $j$ 之间的权重,$k_i=\sum\limits_{j}{A_{ij}}$ 表示与 $i$ 相连的所有边的权重和,$c_i$ 表示节点 $i$ 所在的社区,$\delta(x, y)$ 表示 $x$ 和 $y$ 是否相同,是的话为 1,否则为 0。
公式并不好直接理解,进行一定的变换可得 \(\begin{align} Q &=\frac{1}{2m}\sum_{i,j}{(A_{i,j} * \delta(c_i,c_j) - \frac{k_i * k_j * \delta(c_i,c_j)}{2m})} \\ &= \frac{\sum\limits_c{in_c}}{2m} - \frac{\sum\limits_c{tot_c^2}}{2m} \end{align}\)
其中 $c$ 表示社团,$in_c = \sum\limits_{i{\in}c}{\sum\limits_{j{\in}c}{A_{i,j}}}$ 表示社区 c 中所有节点的之间的边权和,$tot_c=\sum\limits_{i{\in}c}{k_i}$ 表示社区 c 中所有节点与其他节点的边权和。
模块度前一项描述的是社团内节点之间的边权,该值越大,模块度越大。第二项描述每个社团中所有节点的边权和平方,分母为常量,当所有节点(严格来说是节点的度,即边权)在不同社区中分布越均匀,第二项越小,模块度越大。(第二项重要程度与社团实际的分布情况有关,比如风控场景社团大小分布极不均匀,就会导致第二项结果偏大,模块度偏小,导致模块度的优化目标与实际场景冲突)
Louvain - 模块度优化
louvain 以最大化模块度为优化目标,根据模块度公式,整个社区的模块度可以以各个社区为单位计算后求和得到,louvain算法的流程如下
初始化
将社团中每个节点都看做一个单独的社区。
阶段1:节点合并
遍历所有节点,计算当前节点脱离当前社区,且加入到邻居节点所在社区时,带来的模块度增益,把当前节点移动到增益最大的邻居节点社区中。
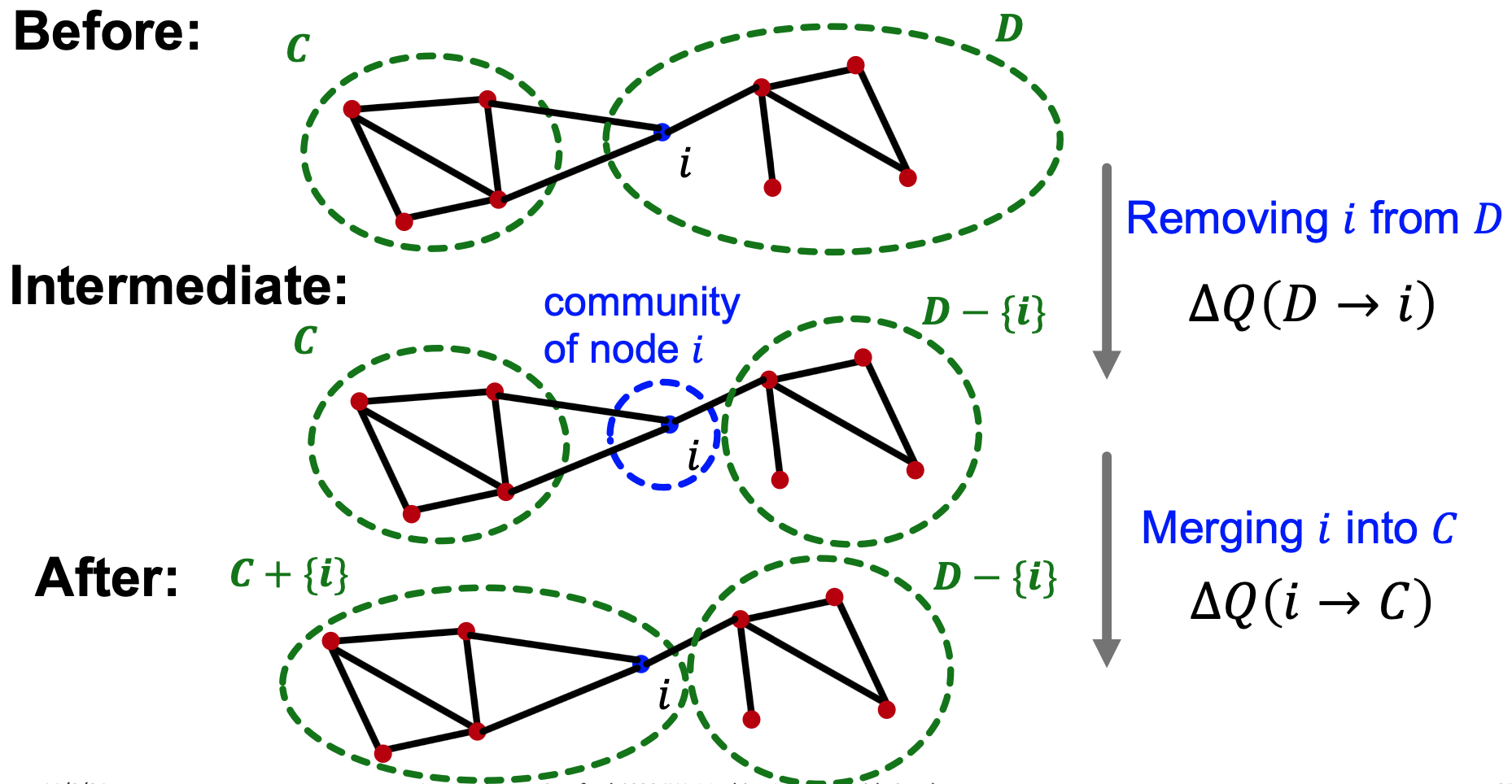
每次计算节点 i 从社团 D 移动到社团 C 中时,根据模块度计算公式可知,此时产生的模块度变化只与当前C、D社区相关,不与其他社区相关,因此计算成本较低,将节点 i 从社区 D 转移到 C 中带来的模块度增益为: \(\begin{align} {\Delta}Q &= {\Delta}Q(C \rightarrow i) + {\Delta}Q(i \rightarrow C) \\ &= \Delta Q(C \rightarrow D) \\ &= (\frac{in_{D+i}}{2m} - \frac{tot_{D+i}^2}{2m}) + (\frac{in_{C-i}}{2m} - \frac{tot_{C-i}^2}{2m}) - (\frac{in_{D+i}}{2m} - (\frac{tot_D^2}{2m}) - (\frac{in_C}{2m} - (\frac{tot_C^2}{2m}) \\ &= \frac{in_{D+i} + in_{C-i} - in_D - in_C}{2m} - \frac{tot_{D+i}^2 + tot_{C-i}^2 - tot_D^2 - tot_c^2}{4m^2} \\ &= \frac{(in_{D+i} - in_D) + (in_{C-i} - in_C)}{2m} - \frac{(tot_{D}+k_i)^2 - tot_D^2 + (tot_{C}-k_1)^2 - tot_c^2}{4m^2} \\ &= \frac{\sum\limits_{i \in D}A_{i,j} - \sum\limits_{i \in C}A_{i,j}}{2m} + \frac{k_i*(tot_C - tot_D)}{2m^2} \end{align}\)
从模块度增益公式中可以看出,节点 $i$ 与社区 D 中节点的边权比与社区 C 中的边权大的越多,越容易使节点 $i$ 转移到 D 中。第二项代表当社区 C 比社区 D 大的越多,越容易发生节点 $i$ 从 C 到 D 的转移,使得社团的整体分布更均匀。
直至节点移动不再产生增益,阶段1停止。
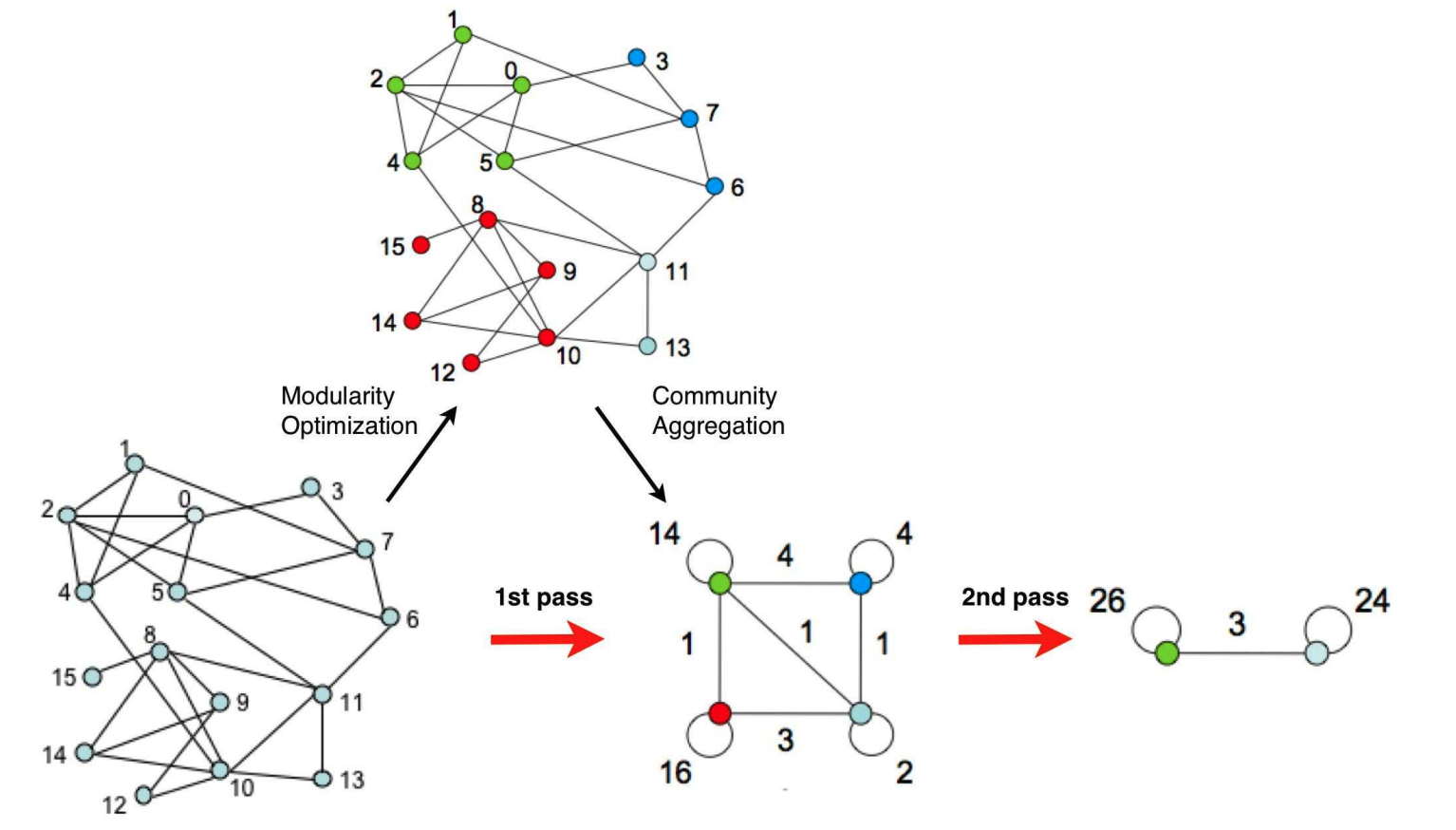
阶段2:社区聚合
将同一个社区的多个节点,融合为一个新的节点,社区内节点之前的权重后续不再使用,当前社区与其他社区之间的权重为两个社区所有节点的权重和,从而构建出新的图结构。 回到阶段1不断迭代,直至图结构不再产生改变。
louvain基于贪心算法实现,阶段1不断进行节点移动的尝试,复杂度可能超过 O(max(M, N)),因此整体最坏的复杂度不好预估,实际情况中的平均复杂度为 O(nlog(n)),当每一轮迭代中节点数量降低一半时,能达到平均复杂度。
整体流程如下:
优缺点
优点
- 平均时间复杂度较低,计算速度相对较快。
- 支持定义边权
- 包含层次结构的社团,可以依据社团大小、社团特殊属性来限制最后形成的社团。类似决策树中根据增益、叶子节点数量来限制节点分裂
缺点
- 多轮迭代,不支持流式系统
- 最差时间复杂度较大,小概率遇到边界数据时,耗时较长。
- 实际情况中数据分布不均匀时,模块度定义的第二项会产生一定负干扰。
优化思路
模块度的最优求解本身是个 NP 问题,即时间复杂度为 O(M!),常规数据中无法在短时间内求到最优解。louvain就是利用贪心算法对求解过程做了一定优化,但在 louvain 的基础上,或许还可以做以下优化:
- 在阶段1只进行一次节点合并,保证获取的结果更优,但时间复杂度上升到为稳定的 O(M*N)
- 利用边介数的概念对社团中的边进行关于合并优先级的排序,边介数定义为:社团中任意两个点的最短路径通过该边的次数。边界数越大,越应该更早进行该边的合并。但边介数的计算方式需要计算任意两点的最短路径,复杂度为 O(M*N),计算完毕后节点合并的复杂度为 O(M),则整体复杂度为 O(M*N)。 此方案虽然整体复杂度较高,但因不需要多次迭代,相比 louvain 更容易适配到流式计算系统中,每次新增一个节点和边时,需要的计算量为 O(M)。
- 实际数据中社团分布不均匀时,建议降低模块度中第二项的权重。
以上思路暂未实现考证,欢迎读者实践、讨论。
参考
原始paper:https://arxiv.org/abs/0803.0476 stanford keynote:http://web.stanford.edu/class/cs224w/slides/14-communities.pdf louvain:https://towardsdatascience.com/louvain-algorithm-93fde589f58c 模块度优化:https://www.cnblogs.com/fengfenggirl/p/louvain.html