特征工程
1. 数据清洗
缺失值处理:1)缺失。2)填充0、均值、中位数 无效值:1)只有一个取值。2)无区分度。
2. 特征构建
2.1 单特征处理
分类特征:label encoder,oneHot encoder,target encoder
特征衍生:绝对值、平方、对数。对树模型作用不大。
特征分箱:等频、等距、卡方
时间:年、月、日、时、分;
2.2 特征组合
统计特征:计数、最大、最小、均值、求和、方差、中位数
多项式特征:特征组合,组合的特征数量随 degree 指数增长,可参考 sklearn.preprocessing.PolynomialFeatures
N-to-N:核函数,比如直角坐标转极坐标
时序特征:密度、连续上升/下降次数
文本特征:NLP
图像特征:CV
特征扩散:引入拓扑关系
2.3 不同的特征工程方法在不同模型上的表现
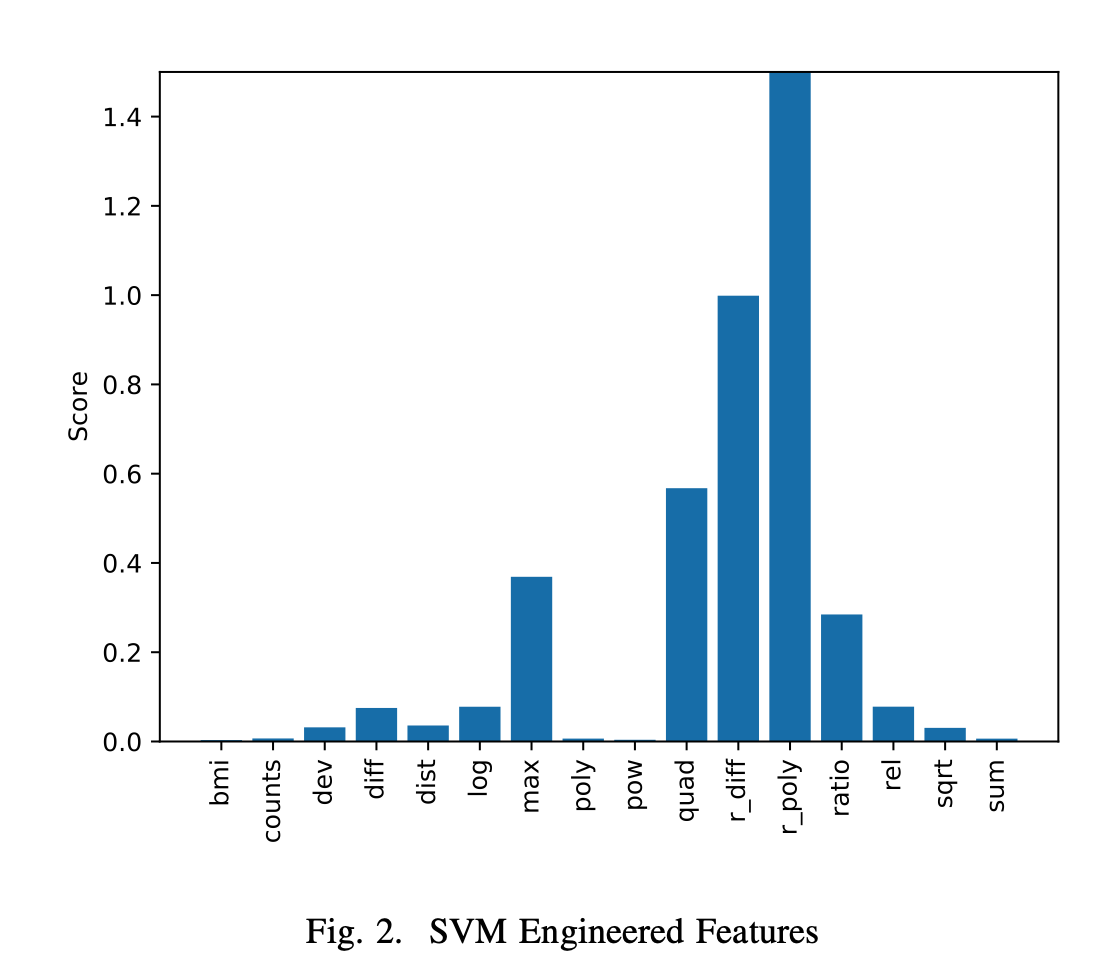
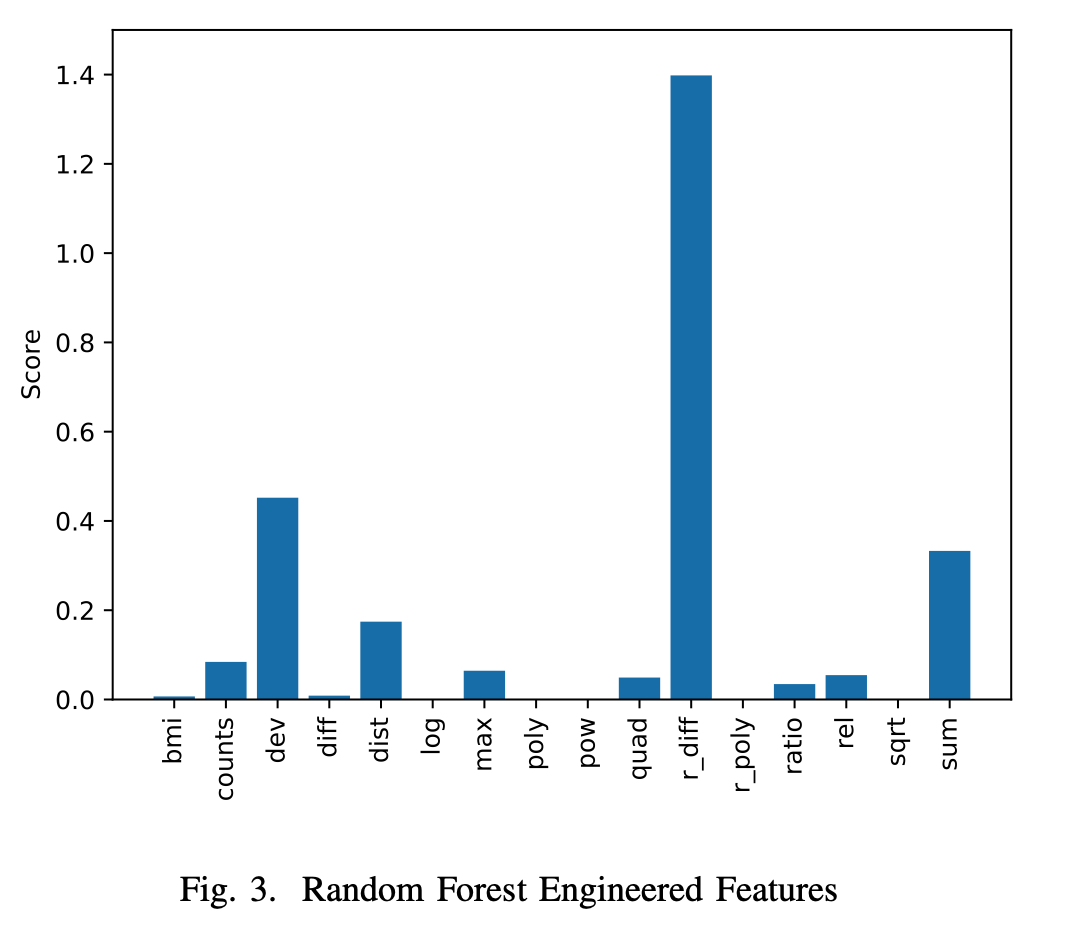
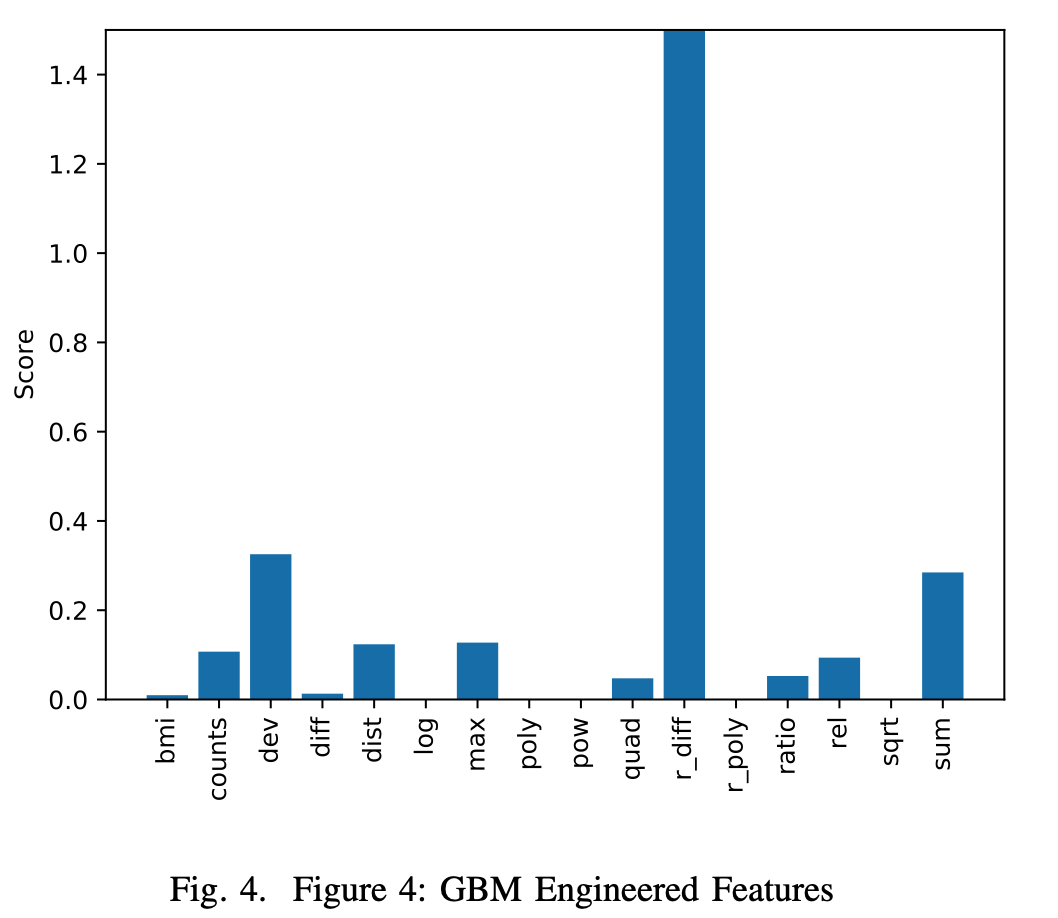
本文对比了不同模型构造不同特征的能力。
模型:DNN, SVR, RF, GBM
特征:计数、求和、标准差、剪发、分布、log、max、多项式、指数、二元方式根的距离、r_diff、r_poly、比例、平方根、欧式距离。
四种模型构造 r_diff 特征的能力都最弱
$$
y=\frac{x_1-x_2}{x_3-x_4} $$ 表现最好的是DNN,学习能力最差的依次是 r_diff, max, dev
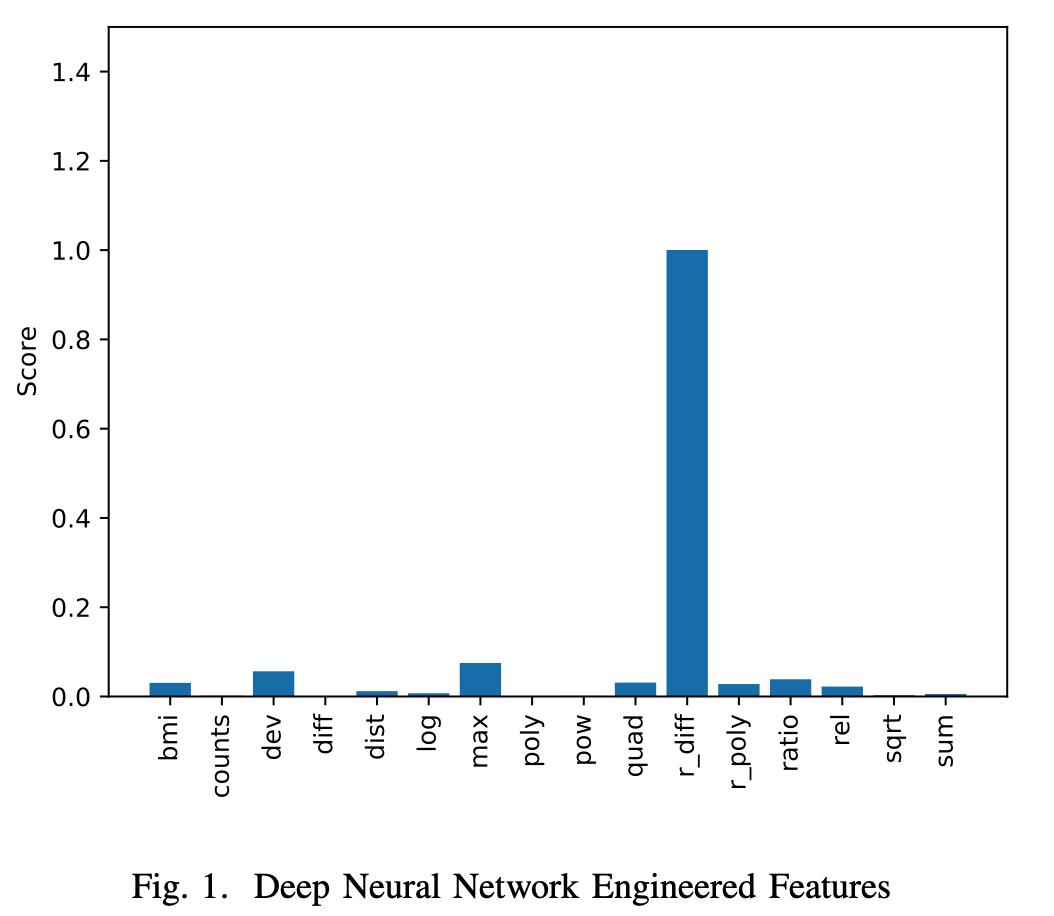
SVR表现最差,但适合跟DNN搭配。
RF和GBM表现非常类似
3. 特征选择
过滤法:单特征看区分度,IV值
包装法:不断加入/删除特征,看模型指标的变化
嵌入法:看特征权重,可以考虑引入正则。
模型相关:数模型看分裂增益
稳定性:直接影响模型稳定性,考虑以正则的方式加入模型
解释性
Exploratory Data Analysis
特征相关性:主成分分析;相似度;聚类
4. 参考
DONE
特征工程的10个案例:https://www.kdnuggets.com/2018/12/feature-engineering-explained.html
polynomial feature:https://machinelearningmastery.com/ polynomial-features-transforms-for-machine-learning/
spark 特征工程:提供了一些特征分桶、特征标准化的一些接口
featuretools:特征扩展包,通过名字描述特征勾走Exploratory
Data Analysis
autogluon:自动机器学习库
神秘网友:https://hg95.github.io/sklearn-notes/Chapter5/%E8%BF%87%E6%BB%A4%E6%B3%95%E6%80%BB%E7%BB%93.html
TODO
潮汐实验室:https://chengzhaoxi.xyz/19ff6f0a.html