累计局部效应图
从PDP优化
M-plots
PDP 把当前特征值代入所有样本中,会出现部分样本在实际情况中不可能存在的问题,于是就有 M-plots,计算当前特征值对应的预测期望时,只考虑数据集合中存在的样本。
ALE
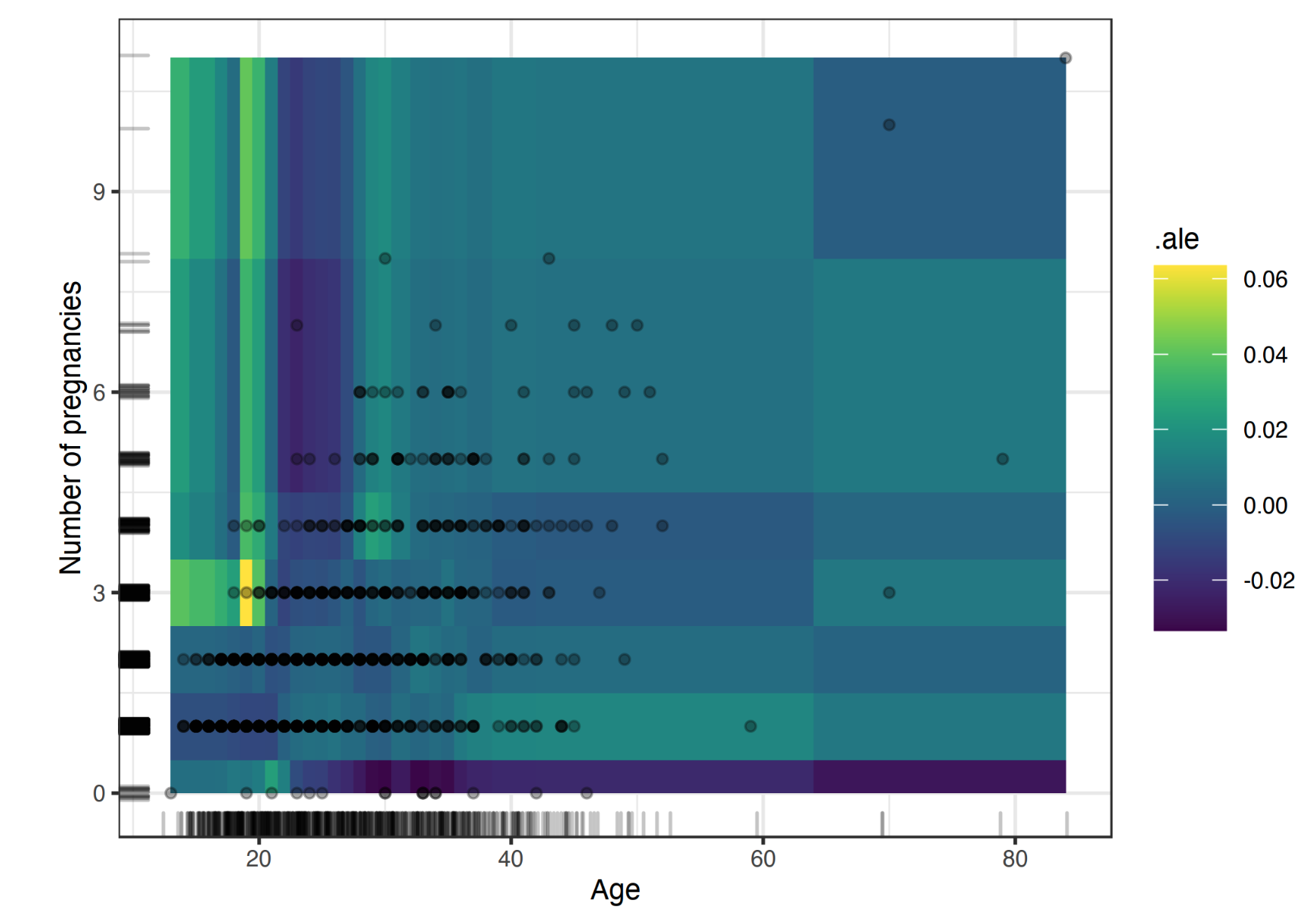
ALE 取同一区间内,预测值的变化作为特征的影响,不同区间累计,构建特征和预测值之间的关系。与 M-plots 不同的是,ALE取预测值的变化作为特征影响,而不是取预测值的均值。 影响:特征在一个小区间内不同取值,模型预测值的差异,或者说预测对特征的导数,作为当前区间的影响。 局部:差异定义在当前的小区间内,只具有局部意义 累计:将影响累计起来,构建特征-预测之间的散点图。
使用
单特征
特征划分区间,针对当前特征区间的样本,将特征值分别改为区间最大值和最小值,进行预测,把预测值的平均值求差,作为当前区间的影响。
两特征
当描述两个特征时,ALE描述特征2在特征1的基础上,对预测值的影响,下图为例,用 $(f(d) - f(c)) - (f(b) - f(a))$ 作为特征 2 在特征 1 的基础上对预测值的影响。
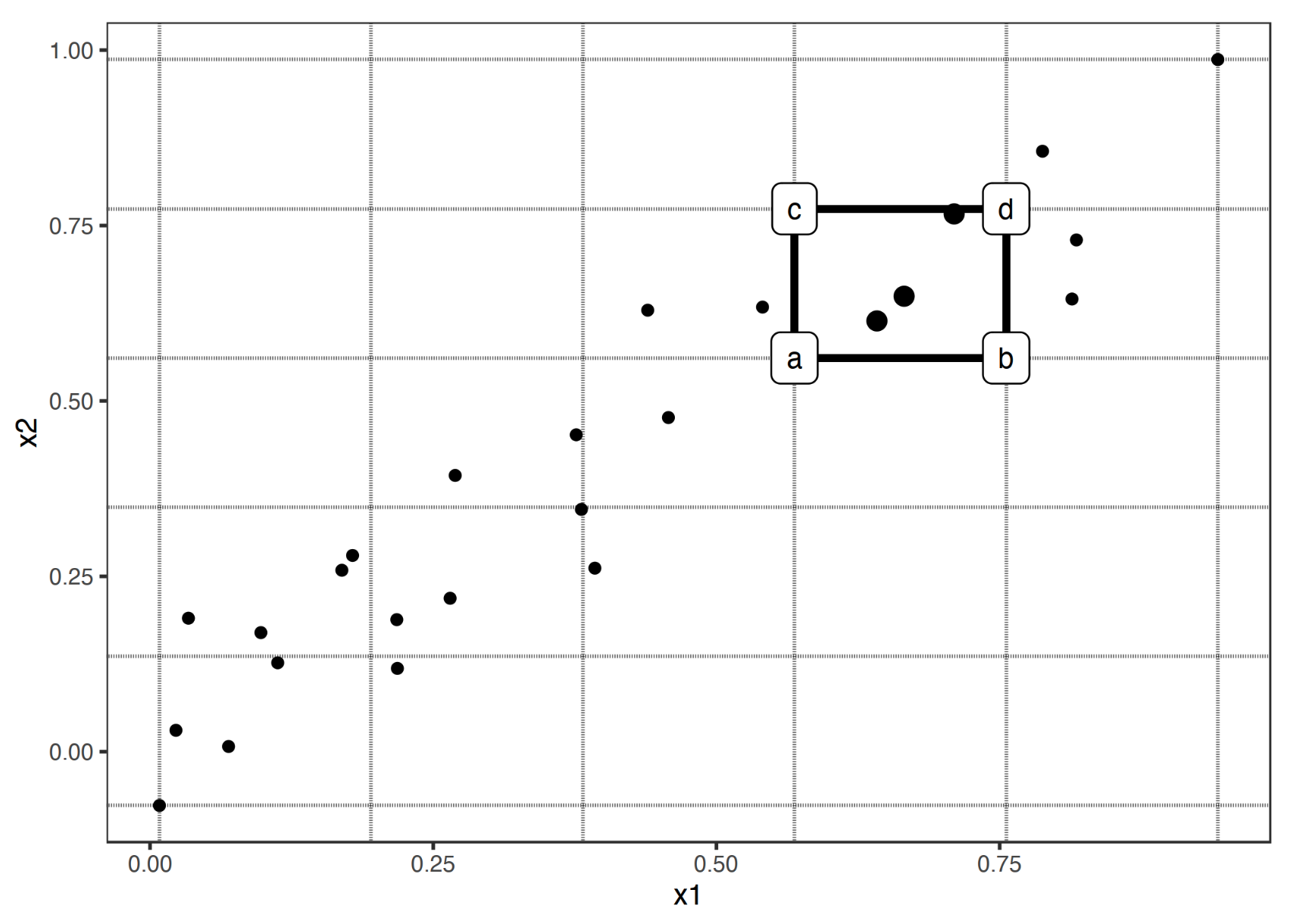
当特征1和2相互独立,该值依然和预测值保持线性关系,当不独立时,能在消除相关性之后考虑特征-预测值之间的关系。
类别型特征
类别特征和数值特征不同的是没有顺序,那给他们排一个顺序就好了。 方法:针对类别特征中任意两个取值,根据其他特征的分布判断这两个取值的相似度,即可以获得类别特征两两取值的相似度矩阵,可以通过 multi-dimensional scaling 降维,降低到一维,从而对类别特征做了排序。 举例:现在对季节这个类别特征做数值化,可用的数值特征为温度
- 取季节中 春、夏 两个取值,根据「春」和「夏」对应的温度分布计算他们的相似度
- 同时计算季节中 春夏秋冬四个取值任意两个之间的相似度,得到季节之间的相似度矩阵
- 对矩阵降维到一维,完成类别特征的数值化
案例
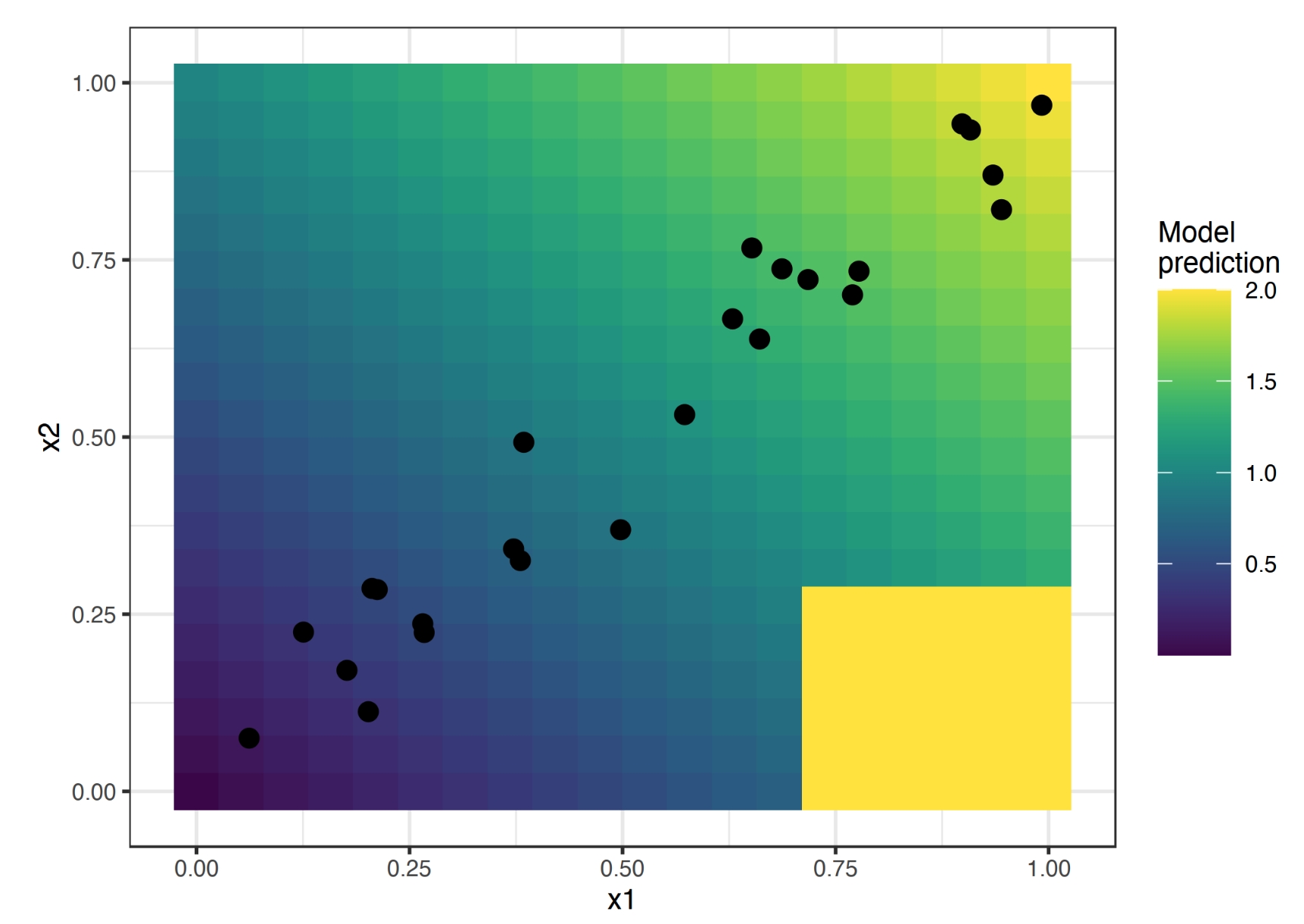
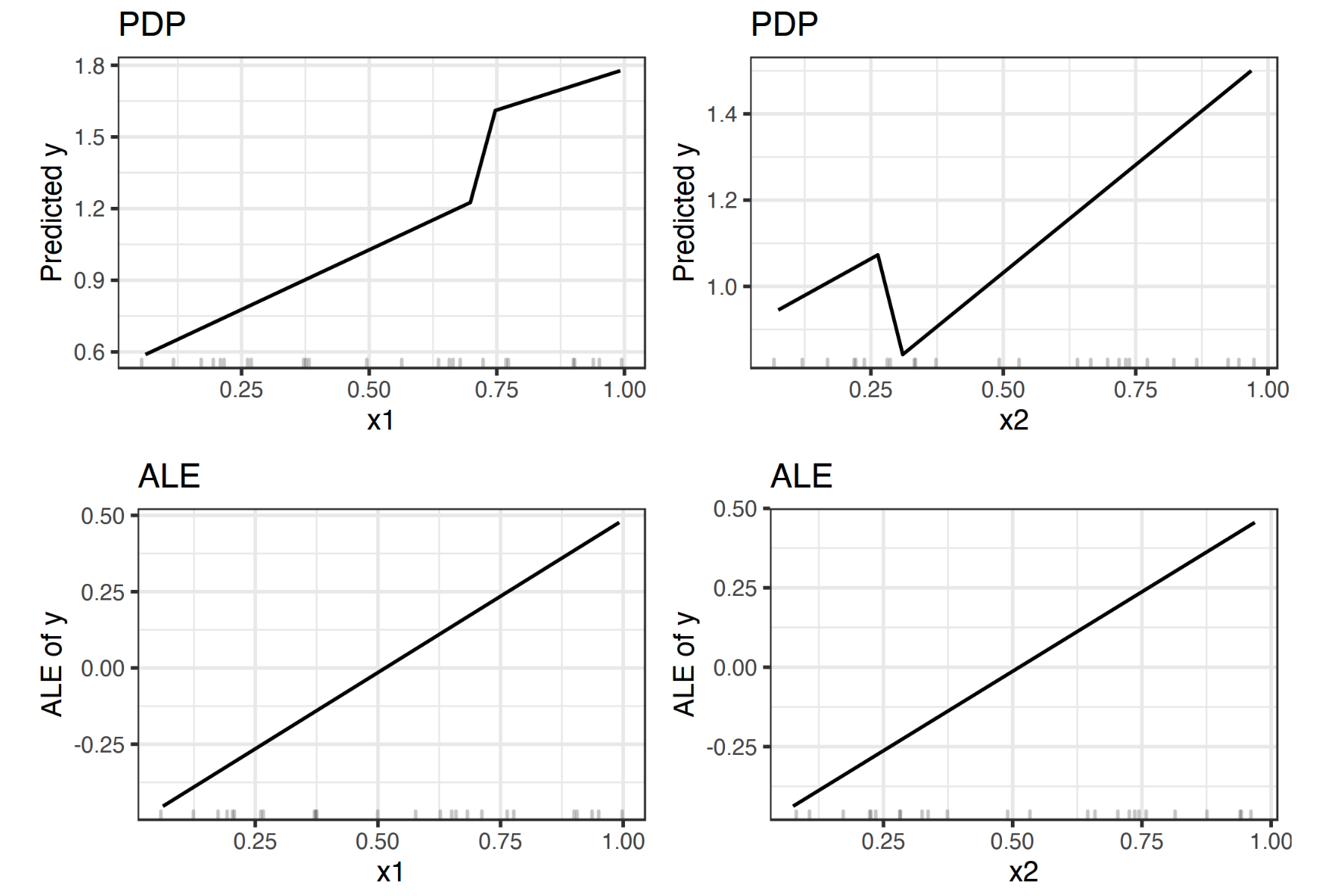
案例1:右下角的极端情况,会出现 PDP 获取了实际中不存在的样本,而 ALE 展示的效果就很好
案例2:特征之间用线性回归做预测,以衡量特征的相关性。(为什么突然提这个?
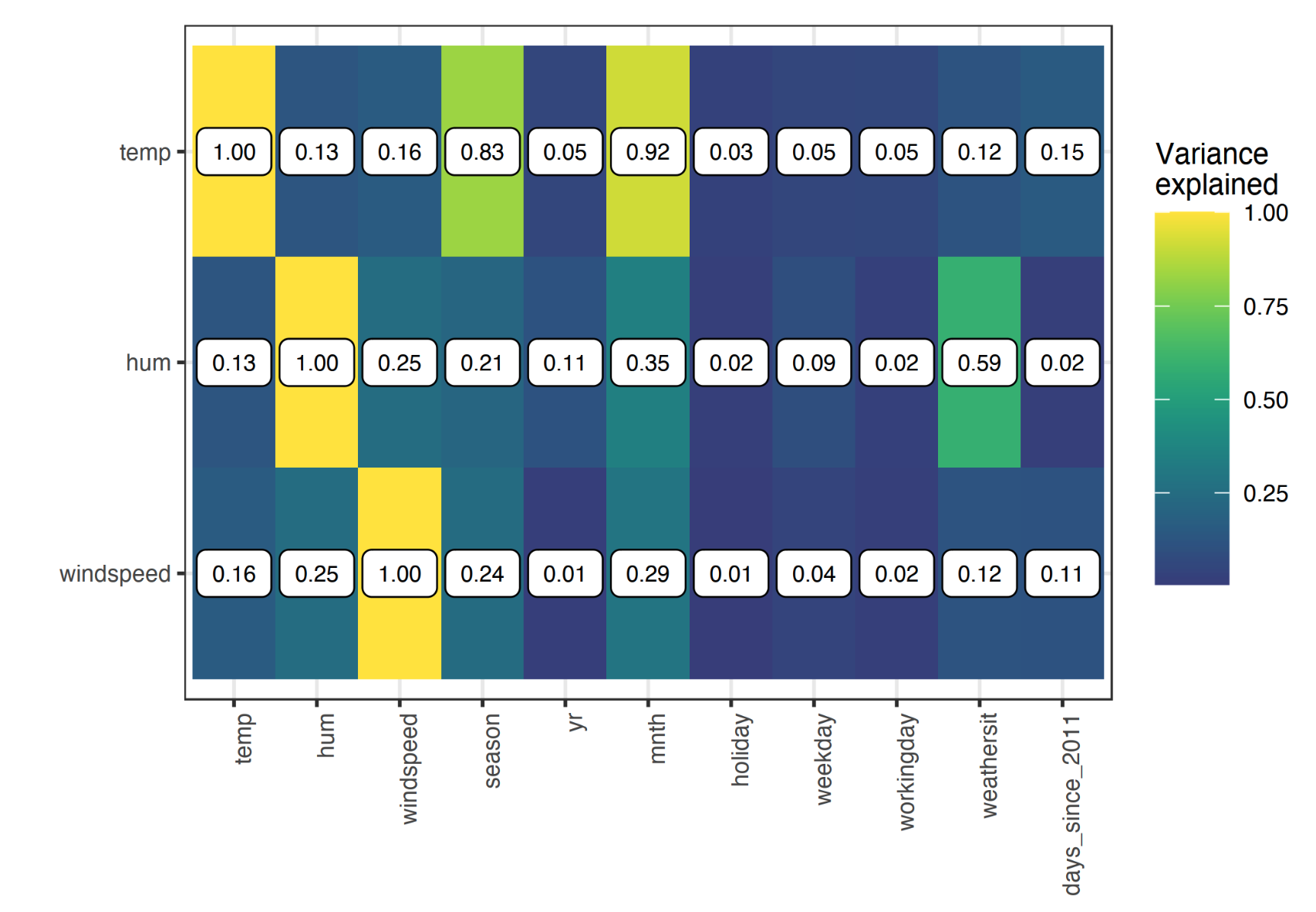
案例3:特征相关性较高,单特征看到的影响并不置信。
特点
优点
ALE 是无偏的,即使特征之间存在相关性,也是有效的。 ALE 效率更高,时间复杂度 O(n),PDP复杂度应该在 O(n*m) 量级 解释性很清晰:1)表达预测值的相对变化。2)以0为中心,每个点都是相对平均值的贡献度。3)2D ALE 显示特征间的关系。
缺点
局部:不同区间所用到的样本都不相同,解释具有局部性。而且在特征极度相关时,单维度的 ALE 是无效的。 和LR不吻合:当特征相关时,ALE 的解释数据和LR的参数不吻合? 波动大:但划分的区间数据量过多,ALE曲线波动较大,当区间数量较少,结果并不置信。没有完美的方案。 没有ICE曲线:PDP 有ICE去曲线。ICE曲线是啥? Second-order effect plots can be a bit annoying to interpret 实现更复杂且不直观 特征强相关时,仍然不好解释:分析两个特征同时变化时才更有意思,而不是单特征的变化? 特征不相关时,PDP更好 缺点很多,但使用法则:使用ALE而不是PDP。emmm
应用
PDP:考虑所有样本,包括实际中不存在的样本,比如房价问题中,房子大小=10平米,房间数量=100个。 ALE:仅考虑数据集中存在的样本,数据集取决于你认为适用的集合。
参考
https://christophm.github.io/interpretable-ml-book/ale.html https://github.com/SeldonIO/alibi https://github.com/christophM/iml https://github.com/blent-ai/ALEPython” 中文翻译:https://github.com/MingchaoZhu/InterpretableMLBook 原文github:https://github.com/christophM/interpretable-ml-book