学习 2022.4
1、dropout 和 cos 组合使用带来的问题
孪生网络中,如果 dropout 这一层用于 cos 计算相似度的话,预测阶段的输出值会比训练阶段的值更大,相差一个 dropout 值:$sim_score_{predict} = sim_score_{train} / dropout$ 这是训练和预测阶段 dropout 用法不一致带来的问题。
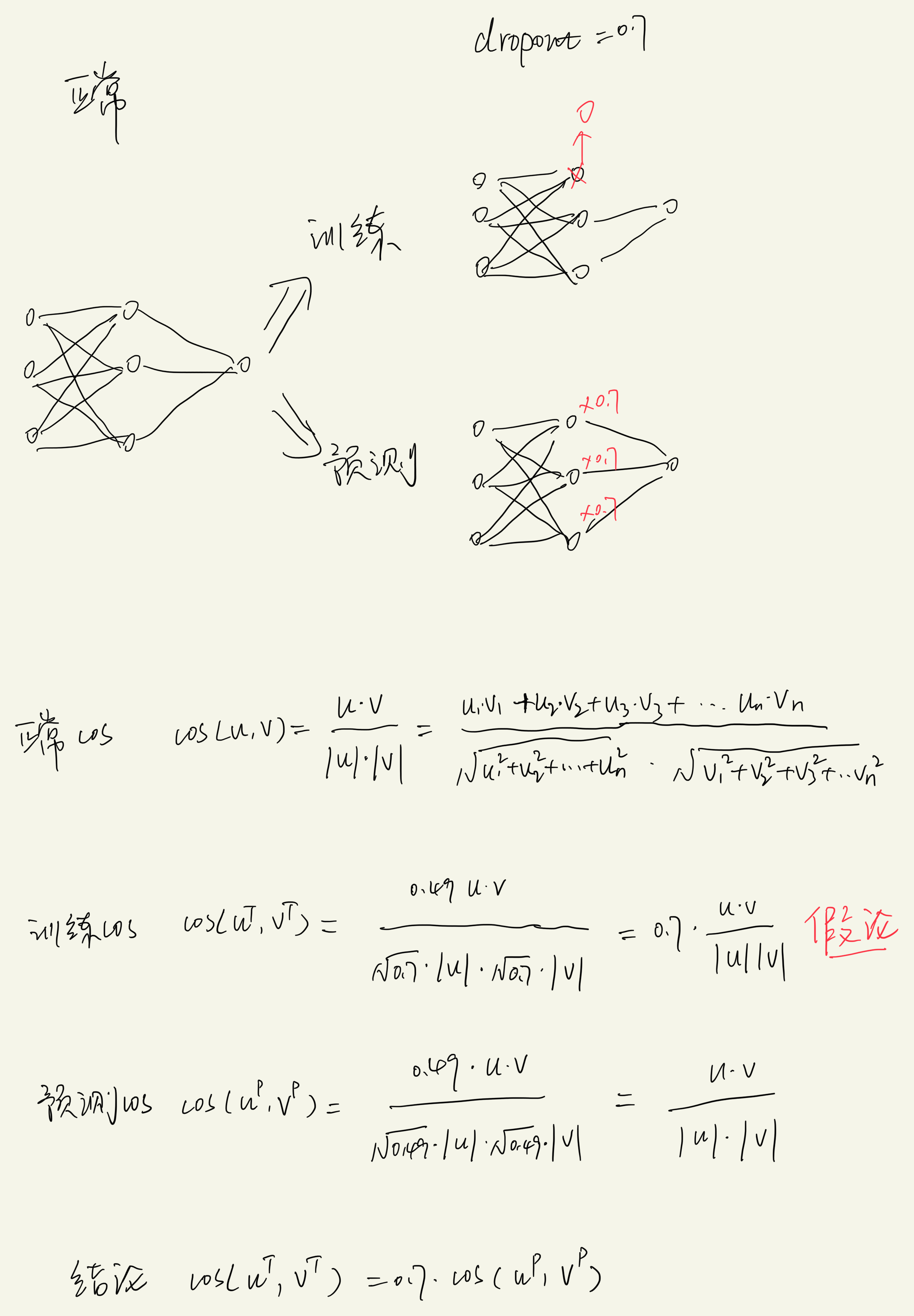
但这个问题包含一个假设:即 dropout 层所有神经元大小相差不多,正常用法中训练和预测要保持一致性也需要这个假设。 2022.4.3
2、Radam 和 adamW
Radam:adam + warmup,动态调整学习率,在训练初期降低学习率,解决 adam 总是找到效果不好的局部最优解的问题。 adamW:adam + 参数L2正则,取名跟 Radam 比较容易搞混。 2022.4.3
3、Xavier 参数初始化
Xavier 参数初始化能够保证神经网络输入层和输出层的方差保持一致,使得输入空间和输出空间的稀疏程度相似,梯度更加稳定。

图片来自:https://cs230.stanford.edu/section/4/
因为输入层和输出层维度不同,取平均,即 var=2/(dim_in + dim_out)
问题:那么,应该保证参数矩阵的哪一个维度 var=2/(dim_in + dim_out)呢? 我觉得保证 dim_in方差一定即可,但使用pytorch做实验发现两个维度的方差都是固定的该值,何必多此一举呢?很奇怪。
pytorch 实验代码
import torch
import torch.nn as nn
torch.manual_seed(2022)
w = torch.empty(100, 200)
x = nn.init.xavier_normal_(w)
var = torch.var(x, axis = 0)
print (var.shape, torch.mean(var), torch.std(var), '\n')
var = torch.var(x, axis = 1)
print (var.shape, torch.mean(var), torch.std(var))
output:
torch.Size([200]) tensor(0.0067) tensor(0.0010)
torch.Size([100]) tensor(0.0067) tensor(0.0007)
reddit提问被删,stackoverflow和知乎还没人回复,好惨。https://stackoverflow.com/questions/71747402/the-variance-of-which-dimension-is-2-dim-in-dim-out-in-xavier-parameter-init
苏神另外一个视角:从几何的角度看初始化策略,以一定均值和方差初始化参数矩阵时,参数矩阵是一个正交矩阵,正交矩阵一个重要的特点就是保证向量的模长不变,即 $||Wx||^{2}=||x||^{2}$,证明了以一定均值和方差初始化参数的有效性。但 Xavier 参数初始化的目标是保证输入和输出向量的方差不变,苏神几何视角是保证模长不变,当向量均值为0时,方差和模长只相差一个常数因子,目标是等价的,很棒。 https://spaces.ac.cn/archives/7180 2022.4.5
4、DEBERTA
论文:DEBERTA: DECODING-ENHANCED BERT WITH DISENTANGLED ATTENTION 源码: 1、self-attention 中求注意力向量时,将上下文关系和相对位置的关系分开计算 atenntion 注意力分数。 2、注意力增强:decode 中,将绝对位置编码加入到 Transformer 块之后、softmax 之前。 3、样本干扰:常规的对抗样本干扰比较类似样本增强的做法,微调样本使得模型保持结果不便,在NLP任务中,我们微调 embedding 层而不是输入样本,但随模型参数量增大(embedding 层增大?),干扰操作带来的抖动就越严重。该论文发现在 embedding 层进行 Layer Normalization 之后加入干扰,对模型效果提升比较明显,特别是在 large 模型中。 2022.4.16