用CNN做query相似度任务
背景
从公司大佬哪儿得知,CNN在query理解上有难以被超越的效果(当然除了bert类的巨无霸模型),就尝试了下。
做法
仍然使用 上一篇博客 中的query相似度任务和数据,同样用孪生网络来做,不过表征query向量的LSTM替换成了CNN,对比CNN和LSTM在query理解上效果的差异,CNN结构参考14年的一篇 paper 来做。
CNN结构先用多个滤波器做卷积,滤波器的某一维与词向量维度大小保持一致,做一维卷积。对每个样本和每个滤波器,都会产生一个一维向量,再做max pooling,得到隐层向量。多个滤波器得到的隐层向量concat起来,再过一个fc全连接层,得到最终的query向量。
网络结构如下
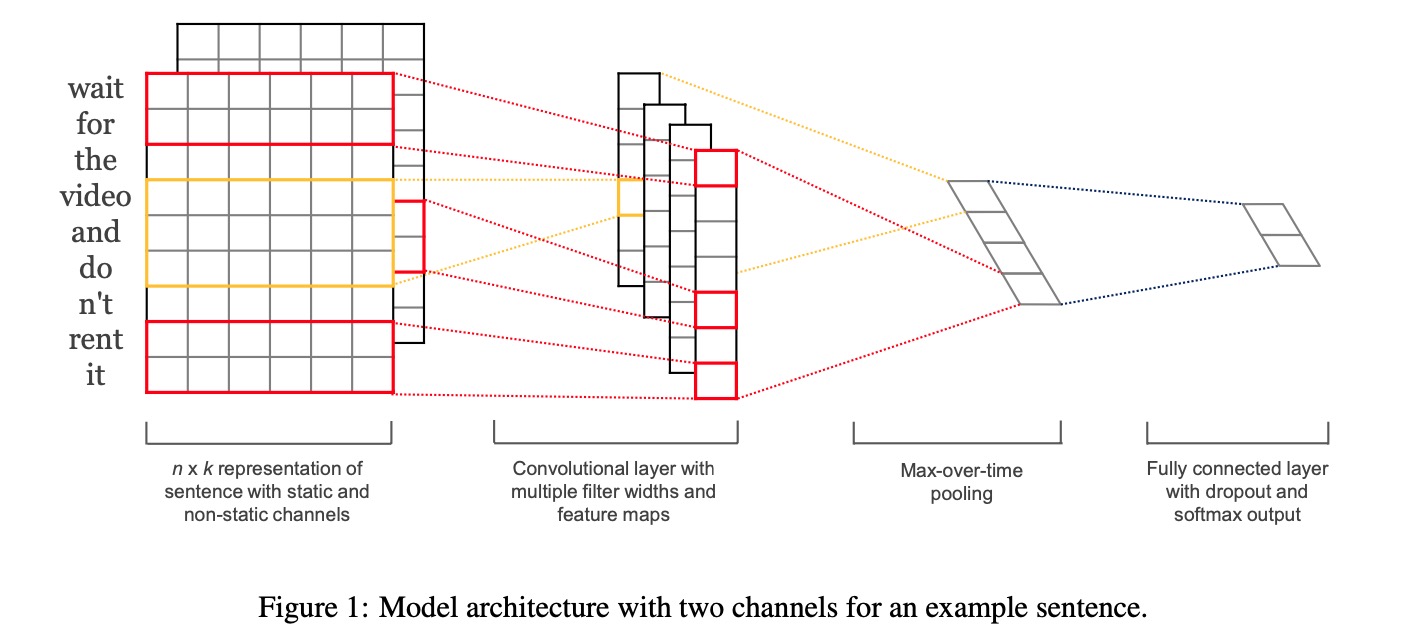
- 一维卷积比较有趣,必须保证滤波器能接受到完整的词向量,所以卷积操作的结果一定是个一维的。
- 不同滤波器的大小可以理解为对当前窗口内的term做的一个映射,从这些term中提取出局部特征输出,后续的max pooling 则取到当前窗口的有效值。假如滤波器大小为2,就是对每两个相邻的term做一个特征提取,如果是3,就是每相邻的3个term做特征提取。试验大多是用的(2,3,4,5)四个滤波器,有尝试过(3,5,7,9),效果并没有显著提升。
实验数据如下: |实验内容|训练集acc|验证集acc| |–|–|–| |LSTM | 0.810 | 0.758 | |cnn base| 0.851 | 0.751 | |Embedding层参数可调| 0.960 | 0.771 | |提高dropout到 0.6| 0.874 | 0.786 | 滤波器用的(2,3,4,5),调整无明显的提升。试验的数据基本是在10个epoch内选择验证集最优的结果。 数据中term数量呈大概的正态分布,以6为中心,分布在[0, 20]之间
结论
- 一维卷积比较有趣。卷积提取局部特征,在短语料场景会比较有效。
- Embedding 层调整大约有2个点的提升。
- 整体相对于LSTM提升3个点。
思考
验证集78%,效果不够好的掣肘在哪里?Embedding 层做成可调,那么w2v向量应该不会是效果差的原因。CNN的网络结构不够好?滤波器太短?但是已经做实验了长的滤波器没有显著提升。